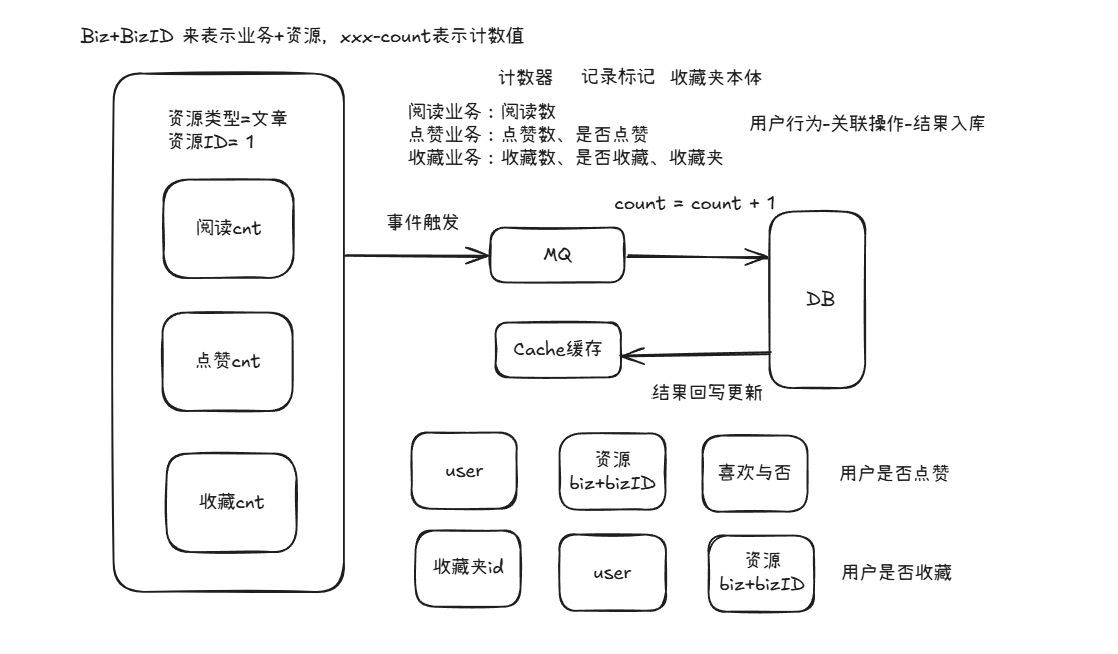
场景说明
在内容、音视频、娱乐等视频APP中,点赞、收藏、阅读几乎是常见的业务逻辑。
比如小红书场景,我们可以收藏一篇博文、点赞一篇博文等。
对外体现的业务逻辑有:
- 点赞:点赞数、用户点赞与否
- 收藏:收藏数、用户收藏与否
- 阅读:阅读数、用户是否阅读过

可行解与问题
对于这个业务逻辑的实现,最粗暴的方式就是文章+计数绑定在一起,每次操作相应的做一个update+1的操作,而用户操作过与否则采取记录进行标记。
但是这里会有一个问题就是过于偶合,点赞、收藏、阅读,这些都是通用的业务逻辑,换个其他场景依旧可以通用。
计数通用化设计
思考一:如何实现资源与计数统一的挂载?
- 解决策略:采取biz+bizID的方式,来表示业务加计数对象,类似的设计还有resource type+resource id、request type+request id
思考二:是否要将点赞、收藏、阅读进行拆分?
- 解决策略:这取决于量级,从业务上,不拆更符合直觉;从性能上,拆可以分散读写压力,但是研发效率可能差。这里采取合并一起的方案进行,中小公司也一般采取这种方案。
计数表结构设计
由于上,可以得出我们的表结构设计:
- 这里创建了联合唯一索引,便于我们快速找到对象的点赞数、阅读数、收藏数等,以及实现UpSert语义。
type Interactive struct {
Id int64 `gorm:"primaryKey,autoIncrement"`
// <bizid, biz>
BizId int64 `gorm:"uniqueIndex:biz_type_id"`
// WHERE biz = ?
Biz string `gorm:"type:varchar(128);uniqueIndex:biz_type_id"`
ReadCnt int64
LikeCnt int64
CollectCnt int64
Utime int64
Ctime int64
}
计数操作与缓存
计数的操作,对于数据库而言,逻辑就是存在则更新,比如阅读数,就是read_cnt = read_cnt + 1。
需要使用Upsert语义:
func (dao *GORMInteractiveDAO) IncrReadCnt(ctx context.Context, biz string, bizId int64) error {
now := time.Now().UnixMilli()
return dao.db.WithContext(ctx).Clauses(clause.OnConflict{
DoUpdates: clause.Assignments(map[string]interface{}{
"read_cnt": gorm.Expr("`read_cnt` + 1"),
"utime": now,
}),
}).Create(&Interactive{
Biz: biz,
BizId: bizId,
ReadCnt: 1,
Ctime: now,
Utime: now,
}).Error
}
除了DB计数,这里还要关注的问题就是,阅读点赞,实际是一个高频访问数据,缓存可以防止高QPS压垮数据。
这里使用Redis的Map即可解决:
- biz-biz-id为Key,value为read-cnt、like-cnt、collect-cnt。
- 这里要做到检查逻辑,就是判断key存在与否,存在则使用HIncrBy进行+1,HIncryBy实现默认0+1,否则需要从数据库Load进来
对于这种检查后操作逻辑,需要保证原子性,Redis就是通过Lua脚本的方式来进行实现。
-- 具体业务
local key = KEYS[1]
-- 是阅读数,点赞数还是收藏数
local cntKey = ARGV[1]
local delta = tonumber(ARGV[2])
local exist=redis.call("EXISTS", key)
if exist == 1 then
redis.call("HINCRBY", key, cntKey, delta)
return 1
else
return 0
end
在获取总数据的时候,如果没有则从DB进行加载,并Load回Cache中。
思考:缓存一致性是否需要进行关注?
- 不精确的原因,并发场景下,数据可能会进行前后覆盖,导致cache和db的数据不一致。
- 不需要,这种计数器,不精确并不会不影响业务逻辑,并不需要进行过多的关心。
点赞标记设计
点赞不同于阅读数的点在于,用户可以标记他是否操作过,即有一个点赞与否的关系绑定。
点赞数本质就是计数处,那么额外需要实现的逻辑就是记录用户的点赞情况。
PS:在大型分布式系统中,点赞应该是一个服务,不会像上面一样,把阅读和点赞偶尔在一起,拆开后,他们可以一起共享高性能的计数服务。
点赞记录表设计
点赞的表设计如下:
- 这里针对uid+biz-type+biz-id设计唯一索引
- 这么设计的原因一方面是加速索引查询,另外一方面是便于标识唯一记录,实现upsert语义
- 这里实现upset语义,也是利用软删除的思路,不用硬删除是因为点赞数据对于公司来说是有商业价值的
type UserLikeBiz struct {
Id int64 `gorm:"primaryKey,autoIncrement"`
Uid int64 `gorm:"uniqueIndex:uid_biz_type_id"`
BizId int64 `gorm:"uniqueIndex:uid_biz_type_id"`
Biz string `gorm:"type:varchar(128);uniqueIndex:uid_biz_type_id"`
Status int //使用true和false,来标识是否点赞过
Utime int64
Ctime int64
}
点赞操作与缓存
操作的话很简单,Upsert即可:
- 注意这里不会对点赞结果缓存,因为用户点开自己的博文,查看点赞与否,认为是一个比较低配的操作
- 但是,如果用户量大起来,即使单个用户的频率少,但是全部用户依旧很大,这个时候需要对架构上进行优化,确保横向扩容可以满足业务的增长
func (dao *GORMInteractiveDAO) InsertLikeInfo(ctx context.Context,
biz string, id int64, uid int64) error {
now := time.Now().UnixMilli()
return dao.db.WithContext(ctx).Transaction(func(tx *gorm.DB) error { // 使用闭包包装事务全部执行
err := tx.Clauses(clause.OnConflict{
DoUpdates: clause.Assignments(map[string]interface{}{
"utime": now,
"status": 1,
}),
}).Create(&UserLikeBiz{
Uid: uid,
Biz: biz,
BizId: id,
Status: 1,
Utime: now,
Ctime: now,
}).Error
if err != nil {
return err
}
return tx.WithContext(ctx).Clauses(clause.OnConflict{
DoUpdates: clause.Assignments(map[string]interface{}{
"like_cnt": gorm.Expr("`like_cnt` + 1"),
"utime": now,
}),
}).Create(&Interactive{
Biz: biz,
BizId: id,
LikeCnt: 1,
Ctime: now,
Utime: now,
}).Error
})
}
收藏夹设计
收藏夹也是一个关系绑定的业务,分为两部分:
- 收藏夹本体:即收藏夹本身的属性
- 收藏夹的资源绑定:收藏夹本体与收藏夹资源1VN的关系绑定
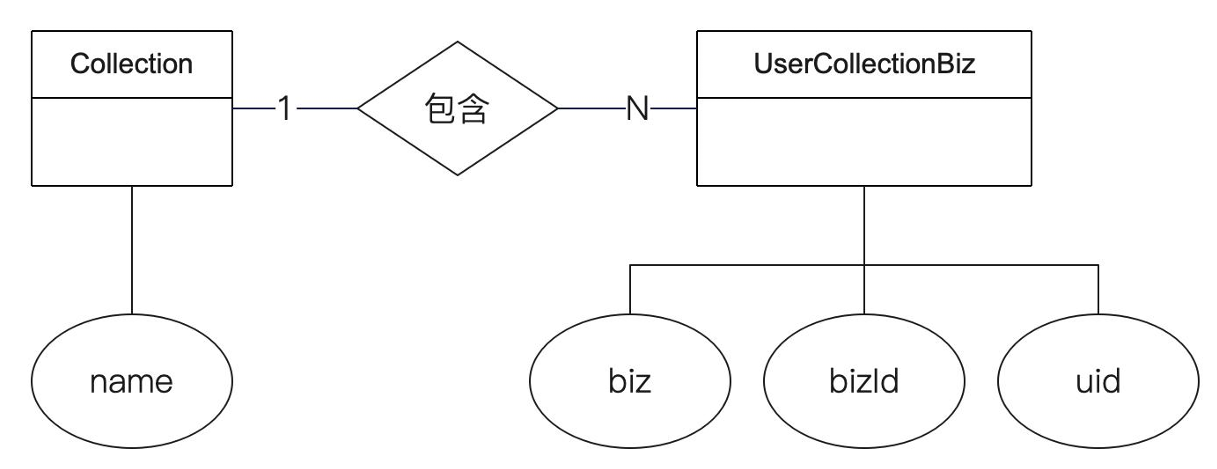
收藏表结构设计
这里设计了两个索引:
- 一个索引cid,用于得到某个收藏夹下面的所有数据
- 一个唯一索引uid-bizid-biz,用于标识用户是否收藏了某个数据
type UserCollectionBiz struct {
Id int64 `gorm:"primaryKey,autoIncrement"`
// 这边还是保留了了唯一索引
Uid int64 `gorm:"uniqueIndex:uid_biz_type_id"`
BizId int64 `gorm:"uniqueIndex:uid_biz_type_id"`
Biz string `gorm:"type:varchar(128);uniqueIndex:uid_biz_type_id"`
// 收藏夹的ID
// 收藏夹ID本身有索引
Cid int64 `gorm:"index"`
Utime int64
Ctime int64
}
聚合逻辑实现
在上面,我探讨了单个业务逻辑,但实际上我们在点开某篇文章的时候,需要详细看到过点赞与否、收藏与否,点赞数等信息。
func (i *interactiveService) Get(ctx context.Context, biz string, id int64, uid int64) (domain.Interactive, error) {
intr, err := i.repo.Get(ctx, biz, id)
if err != nil {
return domain.Interactive{}, err
}
var eg errgroup.Group // 这里使用errgroup来做并发查询
eg.Go(func() error {
var er error
intr.Liked, er = i.repo.Liked(ctx, biz, id, uid)
return er
})
eg.Go(func() error {
var er error
intr.Collected, er = i.repo.Collected(ctx, biz, id, uid)
return er
})
return intr, eg.Wait()
}
在这里还需要说明一点,我并没有对点赞与否这个逻辑进行缓存。
什么时候缓存,什么时候不缓存,都需要对业务有一个判断,切勿过度设计。
如果用户会经常访问某个数据,我们可以采取预加载,反之则没必要进行缓存。
缓存的其他问题,同样也是要基于自己的判断,像一致性问题,不一定要追求100%完成相同。
异步优化
这里每次读,都会去写DB,毫无疑问会给DB造成压力,因此可以采取消息队列进行异步批量化。
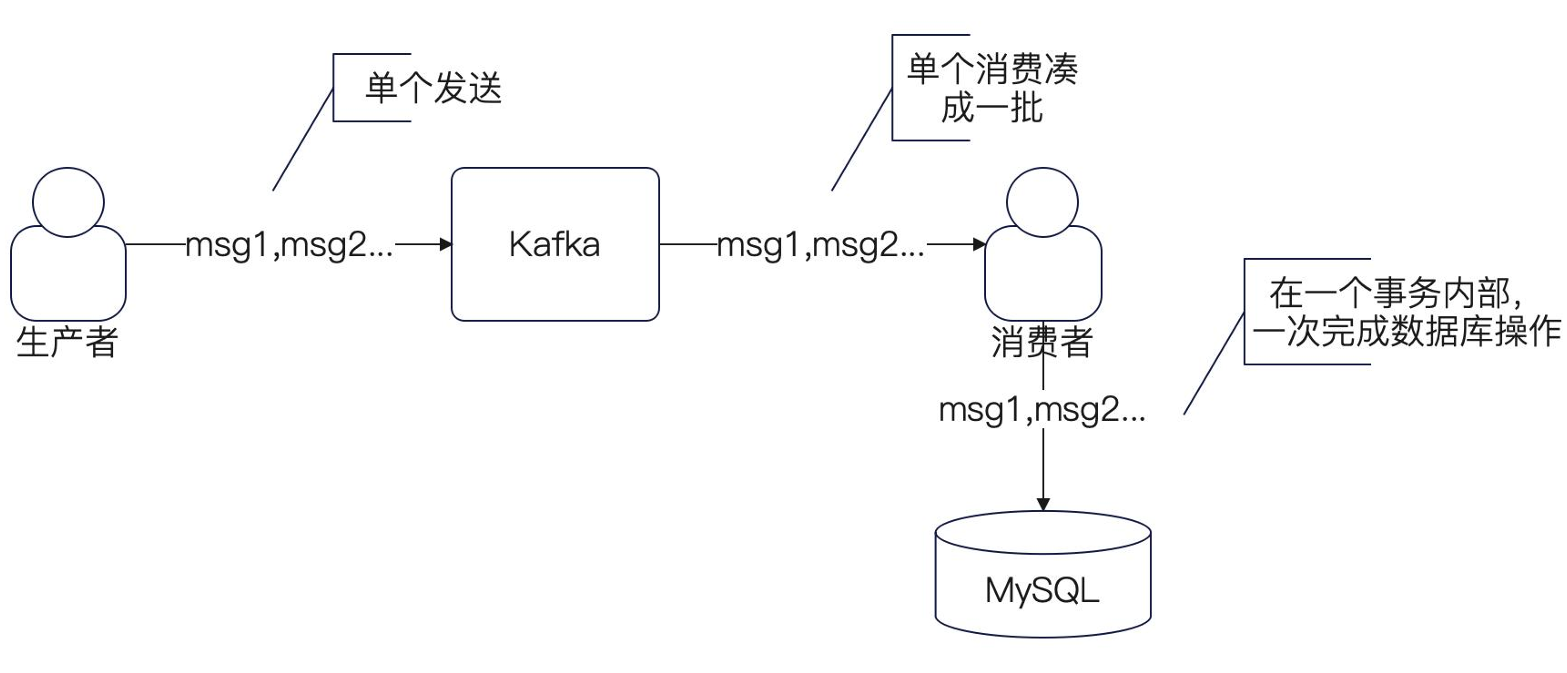
在DDD里面,对于这些逻辑,都归属于领域事件的概念,因此我们可以进抽象设计,后续可以延边为事件驱动架构,对应的业务方进行订阅处理。
举个例子读事件:
type ReadEvent struct {
Aid int64
Uid int64
}
type BatchReadEvent struct {
Aids []int64
Uids []int64
}
生成者一般除了异步发送,几乎无什么优化空间。
func (a *articleService) GetPubById(ctx context.Context, id, uid int64) (domain.Article, error) {
res, err := a.repo.GetPubById(ctx, id)
go func() {
if err == nil {
// 在这里发一个消息
er := a.producer.ProduceReadEvent(article.ReadEvent{
Aid: id,
Uid: uid,
})
if er != nil {
a.l.Error("发送 ReadEvent 失败",
logger.Int64("aid", id),
logger.Int64("uid", uid),
logger.Error(err))
}
}
}()
return res, err
}
对于消费者,这里操作空间比较大,我们可以批量消费。
注意:Kafka一个分区只能绑定一个消费者,也就是说,最多只能扩大至和分区等价的消费者数量,后续扩容并不能提升消费质量。只能在代码层面进行并发优化。
批量消费逻辑,底层帮我们实现了,一般批量底层会实现两个逻辑:超时+数量 双控制
func (i *InteractiveReadEventConsumer) Start() error {
cg, err := sarama.NewConsumerGroupFromClient("interactive", i.client)
if err != nil {
return err
}
go func() {
er := cg.Consume(context.Background(),
[]string{TopicReadEvent},
samarax.NewBatchHandler[ReadEvent](i.l, i.BatchConsume))
if er != nil {
i.l.Error("退出消费", logger.Error(er))
}
}()
return err
}
方案思路汇总