微内核架构与SPI扩展机制探究
技术21-06-2024

1、背景前言
随着技术的不断深入,最近越来越多的任务,需要与中间件相关的扩展打交道。其中一个任务是对网关,基于现有的SPI机制,做插件的扩展化开发。现有的项目采用了SPI+微内核的架构去做架构,但现有内部文档较少,代码结构错综复杂,笔者对于微内核架构以及SPI的应用场景并不熟悉,在缺少前置知识的情况,一股脑的前行显然不可取,故围绕SPI+微内核相关的技术点,调研了业界一些出门的实现,内容包括以下几点:
- 微内核架构与RPC框架架构探讨
- Java内置的SPI机制以及双亲委托的理解
- JDBC的SPI机制运用
- Tomcat利用SPI机制做的环境隔离
- Dubbo的SPI模块设计以及功能亮点
- springboot的自动装配理解
因为网关与RPC有很多相似的点,都是在微服务的背景下,对安全认证,流量控制,日志,监控等功能,做了一个集中的管控处理,故在调研上,参考了较多RPC相关的资料。最后基于对SPI的理解,围绕网关的业务需求,自己实现了一个简单的demo。
注:本文来自个人的学习实践记录,大部分信息参考互联网的公开资料,无泄露内部任何信息。
2、微内核架构
2.1 什么是微内核架构
《软件架构模式》这本书这样介绍到:微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然模式。基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的。然后,很多公司也在开发、发布自己内部商业应用像有版本号、说明及可加载插件式的应用软件(这也是这种模式的特征)。微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
微内核架构包含两类组件:核心系统(core system)和插件模块(plug-in modules):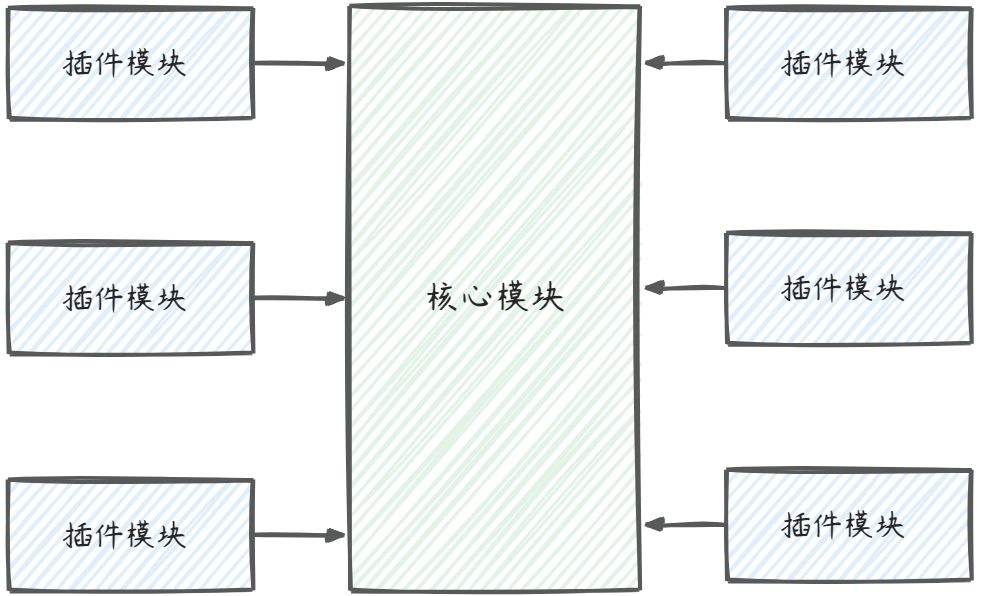
核心模块提供所需的核心能力,插件模块提供扩展系统的功能。因此,基于微内核的系统架构,非常易于扩展功能。像我们常见的很多产品,如IDEA、Dubbo、APISIX、Vscode,都是基于这种模式来做开发。
2.2 以RPC开发谈微内核好处
通过上面的文字,很难体会到这种架构的好处,我以一个简单的RPC框架所需要的功能开发,来举例说明这种架构的好处。对一个简单的RPC框架,大体需要如下模块,很容易有如下的架构思路: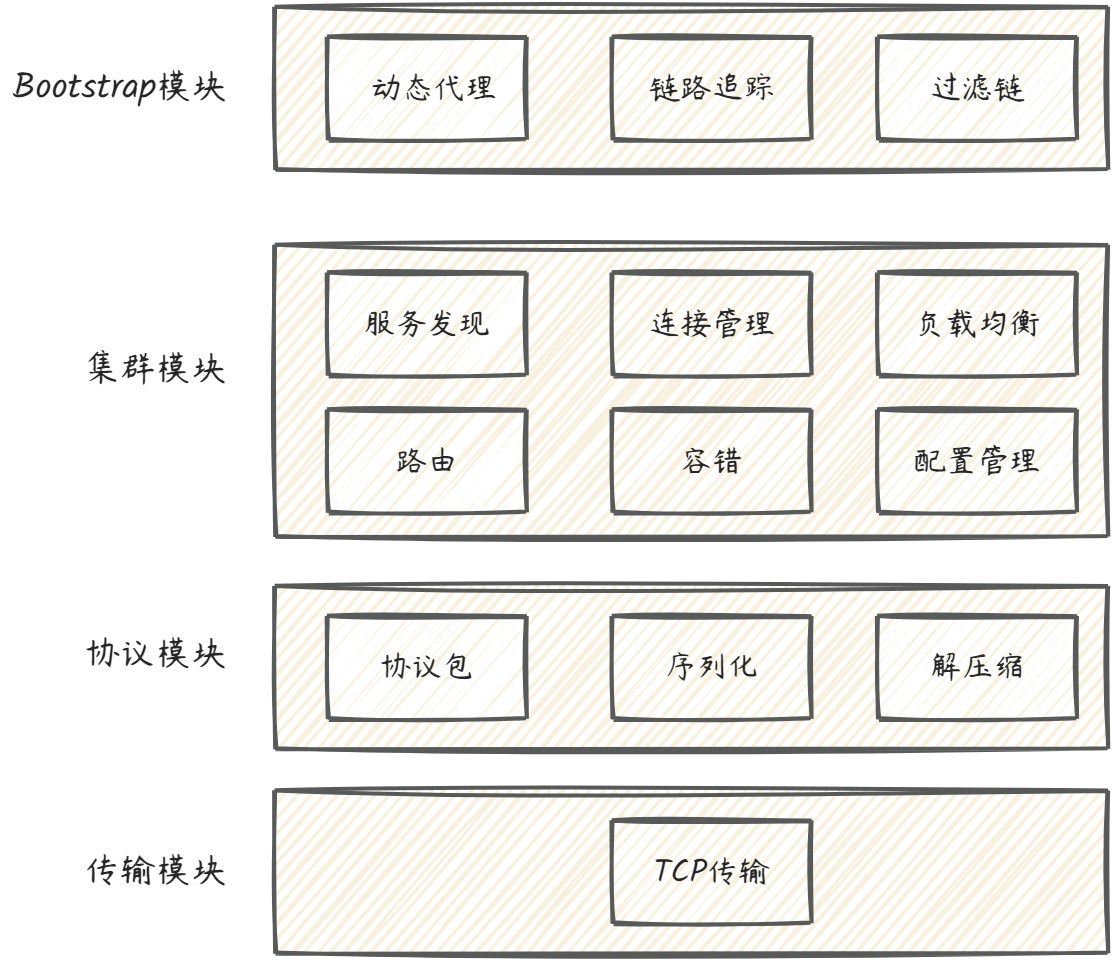
但仅从功能角度设计出的软件架构并不够健壮,系统不仅要能正确地运行,还要以最低的成本进行可持续的维护,因此我们十分有必要关注系统的可扩展性。只有这样,才能满足业务变化的需求,让系统的生命力不断延伸。
其实,我们设计 RPC 框架也是一样的,我们不可能在开始时就面面俱到。那有没有更好的方式来解决这些问题呢?这就是我们接下来要讲的插件化架构。
在 RPC 框架里面,我们是怎么支持插件化架构的呢?我们可以将每个功能点抽象成一个接口,将这个接口作为插件的契约,然后把这个功能的接口与功能的实现分离,并提供接口的默认实现。在 Java 里面,JDK 有自带的 SPI(Service Provider Interface)服务发现机制,它可以动态地为某个接口寻找服务实现。使用 SPI 机制需要在 Classpath 下的 META-INF/services 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体实现类。
但在实际项目中,我们其实很少使用到 JDK 自带的 SPI 机制,首先它不能按需加载,ServiceLoader 加载某个接口实现类的时候,会遍历全部获取,也就是接口的实现类得全部载入并实例化一遍,会造成不必要的浪费。另外就是扩展如果依赖其它的扩展,那就做不到自动注入和装配,这就很难和其他框架集成,比如扩展里面依赖了一个 Spring Bean,原生的 Java SPI 就不支持。
加上了插件功能之后,我们的 RPC 框架就包含了两大核心体系——核心功能体系与插件体系,如下图所示: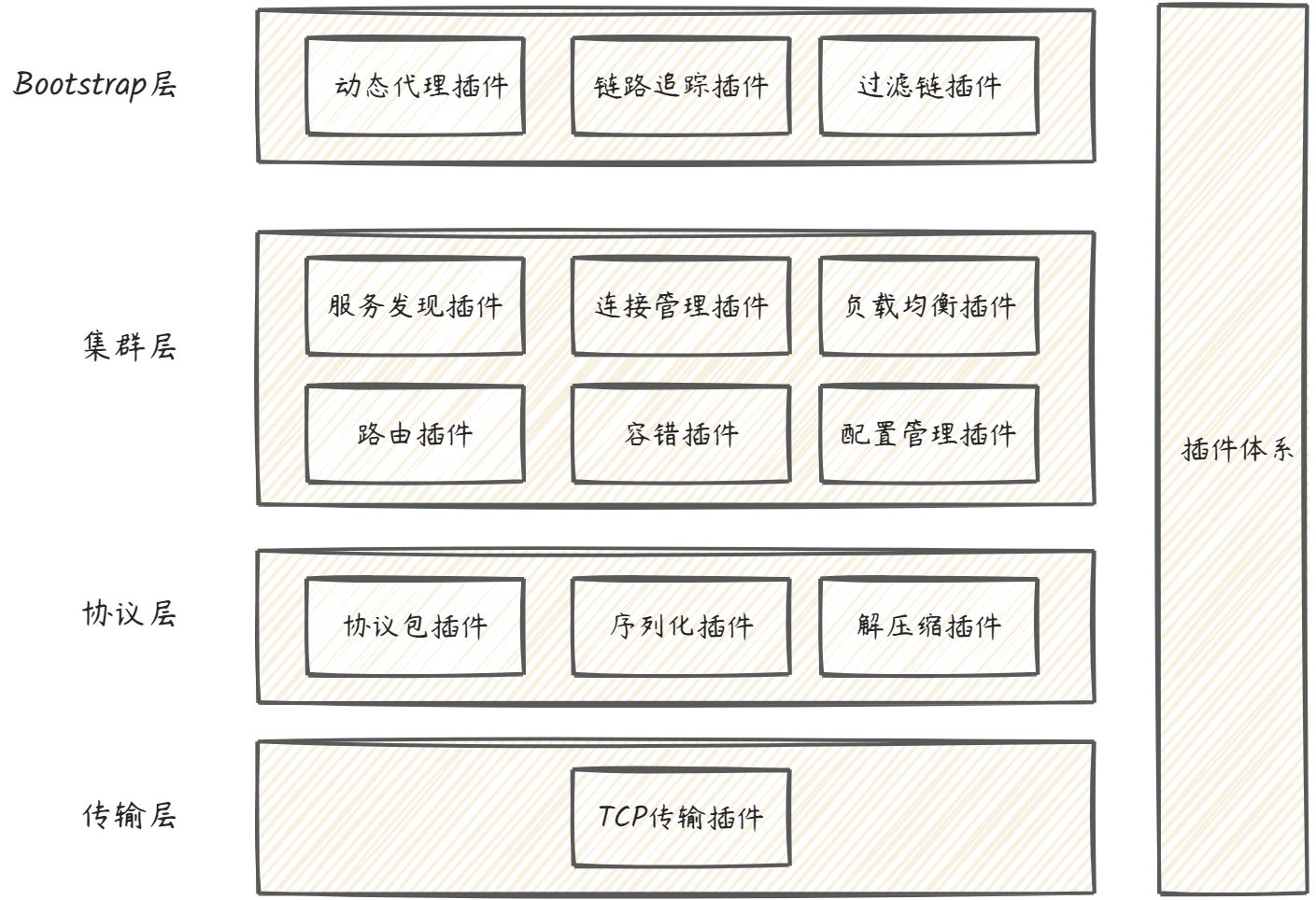
这时,整个架构就变成了一个微内核架构,我们将每个功能点抽象成一个接口,将这个接口作为插件的契约,然后把这个功能的接口与功能的实现分离并提供接口的默认实现。这样的架构相比之前的架构,有很多优势。首先它的可扩展性很好,实现了开闭原则,用户可以非常方便地通过插件扩展实现自己的功能,而且不需要修改核心功能的本身;其次就是保持了核心包的精简,依赖外部包少,这样可以有效减少开发人员引入 RPC 导致的包版本冲突问题。
3、Java内置的SPI探究与缺陷
3.1 使用内置的SPI
通过ServiceLoader去做类的加载:
ServiceLoader<Log> serviceLoader = ServiceLoader.load(Log.class);
Iterator<Log> iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
Log log = iterator.next();
log.log("test java spi");
}
3.2 底层源码分析
在上面知道了ServiceLoader方法load是SPI的入口,那他的调用链如何?
3.2.1 reload方法
最终调用的,是reload的方法:
- 每次reload,会清理 providers 缓存(LinkedHashMap 类型的集合),该缓存用来记录 ServiceLoader 创建的实现对象,其中 Key 为实现类的完整类名,Value 为实现类的对象。
- 最后创建 LazyIterator 迭代器,用于读取 SPI 配置文件并实例化实现类对象。
// 缓存,用来缓存 ServiceLoader创建的实现对象
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
public void reload() {
providers.clear(); // 清空缓存
lookupIterator = new LazyIterator(service, loader); // 迭代器
} 3.2.2 配置迭代器
原先main方法的迭代器,就是LazyIterator的封装:
public Iterator<S> iterator() {
return new Iterator<S>() {
// knownProviders用来迭代providers缓存
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 先走查询缓存,缓存查询失败,再通过LazyIterator加载
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
// 先走查询缓存,缓存查询失败,再通过 LazyIterator加载
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
// 省略remove()方法
};
} 他的方法如下:
- 对于hasNextService,用于查找META-INF/services目录下的SPI配置文件,并遍历:
private static final String PREFIX = "META-INF/services/";
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
// PREFIX前缀与服务接口的名称拼接起来,就是META-INF目录下定义的SPI配
// 置文件(即示例中的META-INF/services/com.xxx.Log)
String fullName = PREFIX + service.getName();
// 加载配置文件
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
// 按行SPI遍历配置文件的内容
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析配置文件
pending = parse(service, configs.nextElement());
}
nextName = pending.next(); // 更新 nextName字段
return true;
} - nextService,负责实例化实现类,并把provider缓存起来:
private S nextService() {
String cn = nextName;
nextName = null;
// 加载 nextName字段指定的类
Class<?> c = Class.forName(cn, false, loader);
if (!service.isAssignableFrom(c)) { // 检测类型
fail(service, "Provider " + cn + " not a subtype");
}
S p = service.cast(c.newInstance()); // 创建实现类的对象
providers.put(cn, p); // 将实现类名称以及相应实例对象添加到缓存
return p;
} 3.3 回归本质
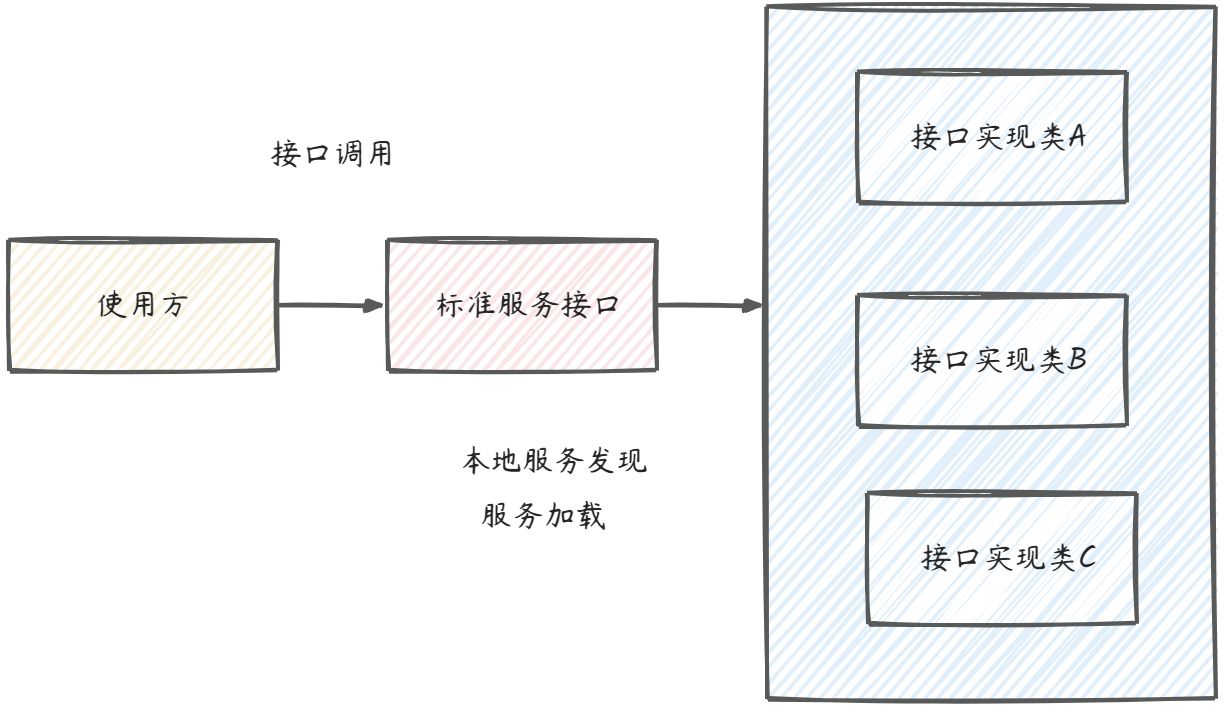
SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。
3.3.1 双亲委托
而每当说到类加载,自然也就离不开类加载机制本身。在Java里面有一个机制,叫双亲委托: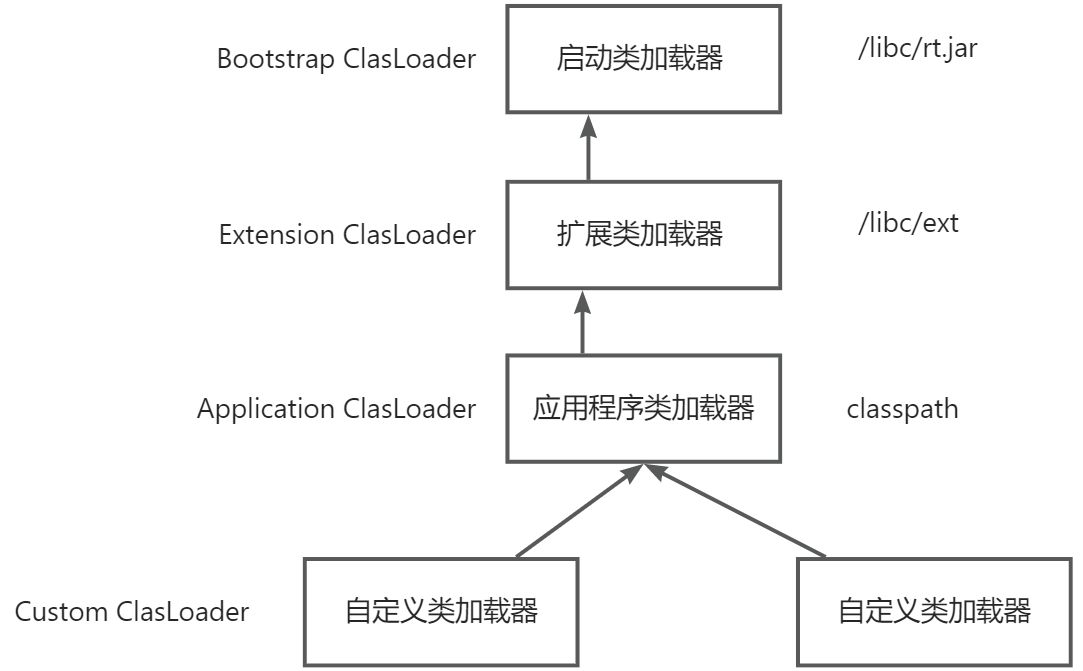
其中最上层的Loader是一个native,剩下两个是类对象。
简单来说,就是为了安全性考虑,类的加载顺序,应该由父类完成,当父类完成不了,再交给子类,这一个点,可以从源码作验证:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
// 首先, 检查请求的类是否已经被加载过了(类加载器的存储空间)
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 如果父类加载器不为空,则用父类加载器加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
// 之所以空是Bootstrap,是因为这个是native
// 如果父类加载器为空(根据上面所说,即为BootstrapClassLoader),则默认使用启动类加载器作为父加载器
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
// 如果父类加载器加载失败,则抛出ClassNotFoundException 异常
}
// 如果抛出ClassNotFoundException 异常,并且还没有被加载到,则调用自己的findClass()方法加载
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
//解析class:符合引用转直接引用
resolveClass(c);
}
return c;
}
}3.3.2 方式一:重写打破双亲委派
从上面可以注意到,这个loadClass是可以被覆盖的,他是抽象类,所以如果我们自己类加载器覆盖了loadClass的逻辑,也就实现打破双亲委派规则,比如下放是一个实例:
@Override
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
//重点重点重点: 这个就是加入了我自己的逻辑,只要在github.huanxin下面的类,都是通过我自定义加载器进行加载
if (name.startsWith("github.huanxin")) {
c = findClass(name);
} else {
c = this.getParent().loadClass(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
PerfCounter.getParentDelegationTime().addTime(t1 - t0);
PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}这里再额外补充一些源码信息:
- JVM的类加载器是分层次的,他们有父子关系,每个类加载器都持有一个parent,注意Bootstrap是native,故为空
- defindClass是一个工具方法,调用native方法将字节码数组解析成一个Class对象
- findClass职责是找到class文件,读到内存中得到字节码数组
- loadClass是一个public方法,对外提供服务接口,完成类的加载
3.3.3 方式二:SPI如何打破双亲委派
关于双亲委派的定义:父类加载器加载不了的时候,下放回来子类加载器去加载。也就是说,父类加载器这层级并没有加载到这个类。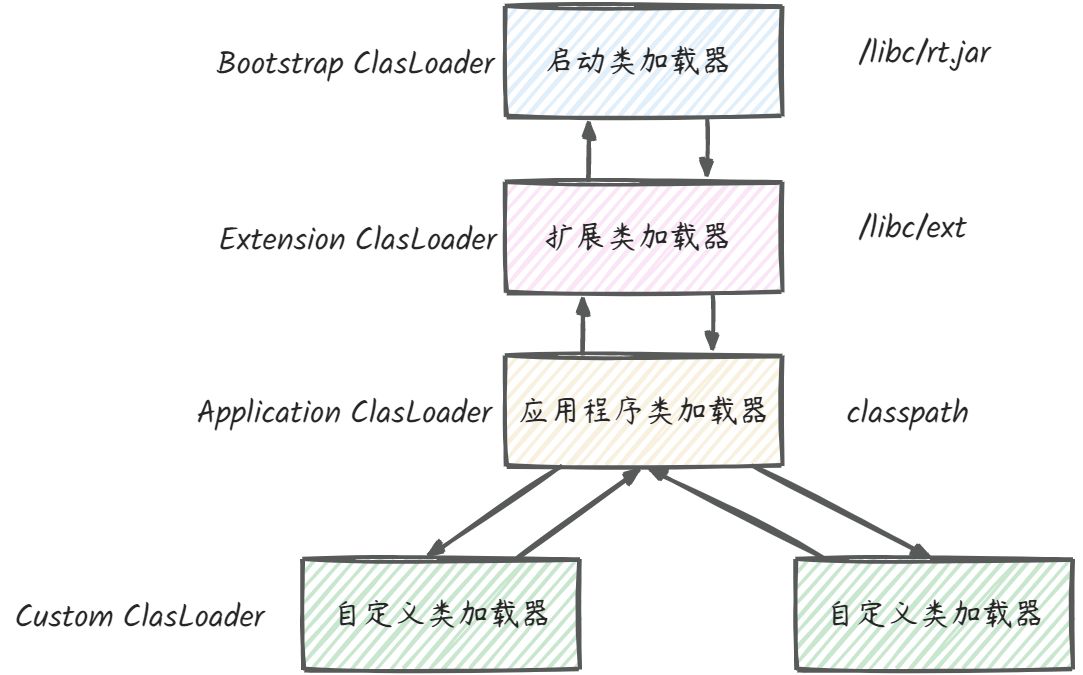
而对于SPI来说,他是这样的,我们知道ServiceLoader是核心类,他会在Bootstrap层级加载,而对于他来说,没有能力去加载我们的业务类,所以他使用了当前的应用类来做加载,委托了下方来做加载。后面的介绍可以从源码看出:
- 所以他打破了双亲委派的限制:即不能向下委托和不能委托。
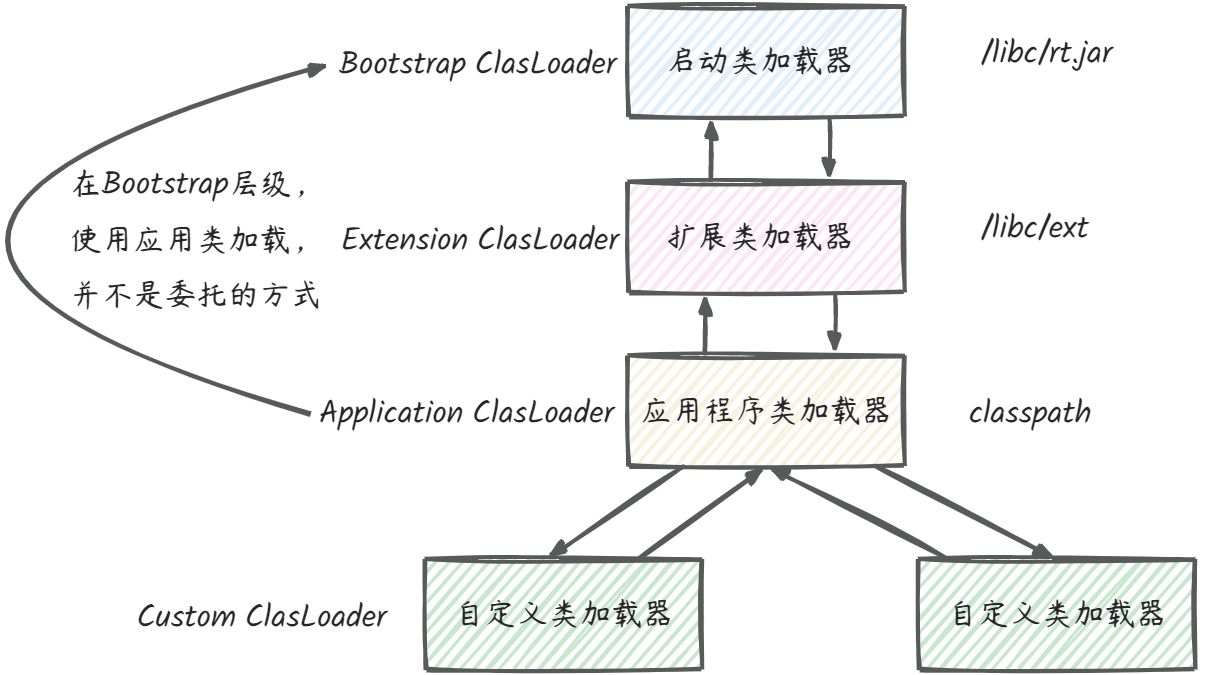
这种设计主要用于解决如下问题,在原先的调用链上:
 自顶向下的本质是一种适配API编码方式的思想,委托链左边的ClassLoader很自然的能使用右边ClassLoader所加载类,但是反过来,右边确无非使用左边的加载的信息。
自顶向下的本质是一种适配API编码方式的思想,委托链左边的ClassLoader很自然的能使用右边ClassLoader所加载类,但是反过来,右边确无非使用左边的加载的信息。
所以无奈之下,使用一种不太优雅的方式,引入了线程上下文加载器,如果线程未创建时,则从父线程继承一个,如果全局没有设置过,那就是应用类加载器。
有了线程加载器,JNDI服务使用这个线程上下文类加载器,就可以加载所需要的SPI代码,也就让父类加载器有能力请求子类加载器完成加载动作,从而打破了双亲委派,提供了SPI编码方式的可能。
3.3.4 SPI的启动类
那么这个SPI的类是什么?
从源码知道,Java玩了个魔术:
public static <T> ServiceLoader<T> load(Class<T> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}他把当前的类加载器,设置为了线程的上下文加载器,那么对于一个刚启动的类来说,他的加载器是谁?肯定是应用程序的类加载器:
public Launcher() {
Launcher.ExtClassLoader var1;
try {
var1 = Launcher.ExtClassLoader.getExtClassLoader();
} catch (IOException var10) {
throw new InternalError("Could not create extension class loader", var10);
}
try {
this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
} catch (IOException var9) {
throw new InternalError("Could not create application class loader", var9);
}
Thread.currentThread().setContextClassLoader(this.loader);
...
}3.3.5 内置SPI的不足
首先是性能上,从上面源码可以看出,他在每次查找服务提高者都需要读取配置文件,且加载所有实现类,清除原先的缓存。
public void reload() {
providers.clear(); // 清空缓存
lookupIterator = new LazyIterator(service, loader); // 迭代器
} 其次是安全性不足,如果SPI提供者写入不合法类名,可能会造成安全风险。
4、业界的应用调研
4.1 数据库驱动加载
很多时候,SPI用于一些驱动代码和业务代码分离的情况,比如说数据库驱动。我们知道,DriverManager和ServiceLoader的类都属于rt.jar,他们的类加载器都是属于Boostrap ClassLoader,而具体的数据库驱动,是属于业务代码,这个启动类自然无法做到。祖先无能力做到,所以交给了子类去做实现。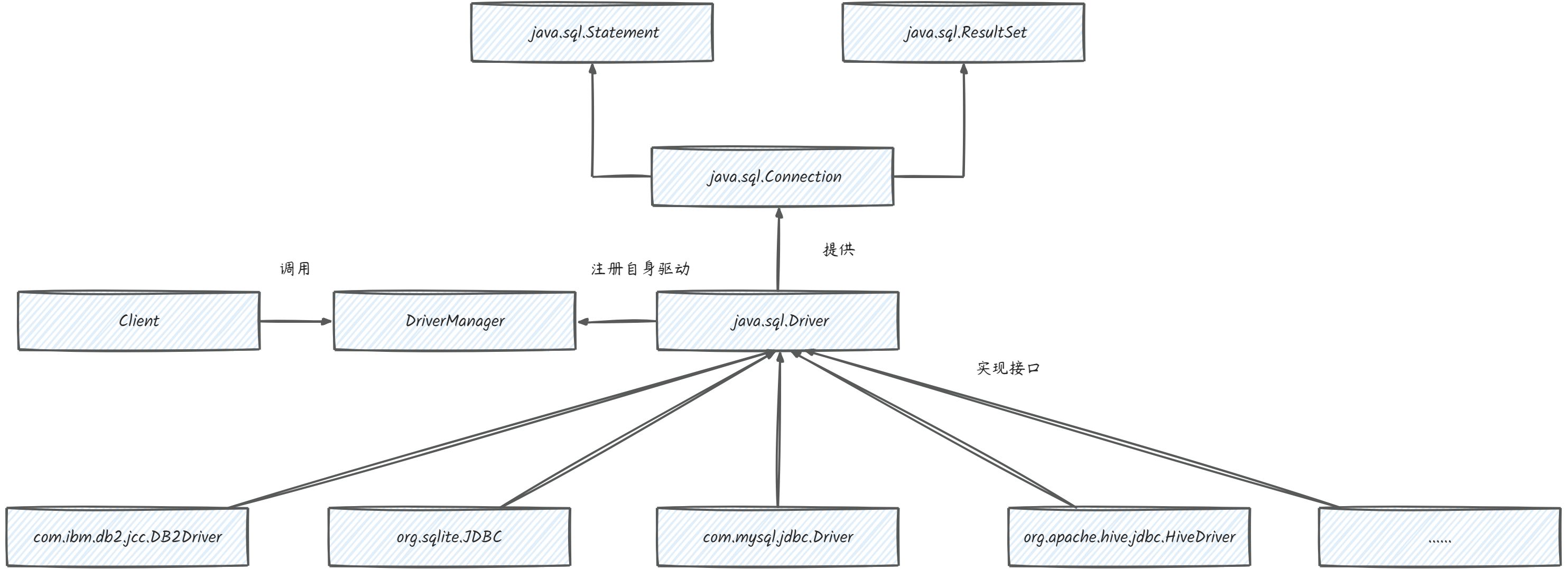
在DriverManager的静态代码块中有如下操作:
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
} 也就是说,只要DriverManger被Java类加载,就会触发staic代码块,调用SPI机制做类扫描实例化:
private static void loadInitialDrivers() {
String drivers = System.getProperty("jdbc.drivers")
// 使用 JDK SPI机制加载所有 java.sql.Driver实现类
ServiceLoader<Driver> loadedDrivers =
ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
while(driversIterator.hasNext()) {
driversIterator.next();
}
String[] driversList = drivers.split(":");
for (String aDriver : driversList) { // 初始化Driver实现类
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
}
} 而MySQL提供的业务驱动,同样有这样的静态代码块,会将对象注册到DriverManger集合中:
static {
java.sql.DriverManager.registerDriver(new Driver());
} 最后通过驱动管理器,我们连接的时候,就能获得对象了:
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {
// 省略 try/catch代码块以及权限处理逻辑
for(DriverInfo aDriver : registeredDrivers) {
Connection con = aDriver.driver.connect(url, info);
return con;
}
} 通过应用程序类加载器,来加载第三方区动,也就是打破了这个规则,将父类的实现,交给子类来做。
4.2 Tomcat环境隔离
Tomcat自己定义了WebAppClassLoader,打破了双亲委派机制,具体实现是重写findClass方法和loadClass方法:
public Class<?> findClass(String name) throws ClassNotFoundException {
...
Class<?> clazz = null;
try {
//1. 先在Web应用目录下查找类
clazz = findClassInternal(name);
} catch (RuntimeException e) {
throw e;
}
if (clazz == null) {
try {
//2. 如果在本地目录没有找到,交给父加载器去查找
clazz = super.findClass(name);
} catch (RuntimeException e) {
throw e;
}
//3. 如果父类也没找到,抛出ClassNotFoundException
if (clazz == null) {
throw new ClassNotFoundException(name);
}
return clazz;
}public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
Class<?> clazz = null;
//1. 先在本地cache查找该类是否已经加载过
clazz = findLoadedClass0(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
//2. 从系统类加载器的cache中查找是否加载过
clazz = findLoadedClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
// 3. 尝试用ExtClassLoader类加载器类加载,为什么?
ClassLoader javaseLoader = getJavaseClassLoader();
try {
clazz = javaseLoader.loadClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 4. 尝试在本地目录搜索class并加载
try {
clazz = findClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 5. 尝试用系统类加载器(也就是AppClassLoader)来加载
try {
clazz = Class.forName(name, false, parent);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
}
//6. 上述过程都加载失败,抛出异常
throw new ClassNotFoundException(name);
}从上面的源码可以看出:
- 第一次找不到对应的类时,先ExtClassLoader去做加载,这一步很关键,目的防止Web应用用自己的类覆盖了JRE的核心类,而Ext会委托Bootstrap,这个时候就防止了覆盖核心类。
- 如果核心类没有这个类,就在本地Web应用目录查找加载
- 最后还是没有,就说明不是Web应用自己定义的类,由系统类加载
注意:Web应用是通过Class.forName调用交给系统类加载器的,因为Class.forName的默认加载器就是系统类加载器。
从上面可以看出,Tomcat的类加载器打破了双亲委派,没有一上来就直接交给父加载器,而是先本地目录加载,为了避免本地目录的类覆盖JRE核心,先调用Ext加载。
那么为什么不先用系统类AppClassLoader加载器?很显然,如果是这样,就变成了双亲委派机制了。所以主要是在系统类AppClassLoader加载器之前,先跑了一遍自己定义的类。
那么问题来了,Tomcat如何做到隔离同名的Servlet?
自己定义了一个类加载WebAppClassLoder,并且给每个Web应用创建一个类加载器实例。
这背后的原理是,不同的加载器实例加载的类被认为是不同的类,即使它们的类名相同。这就相当于在Java虚拟机内部创建了一个个相互隔离的Java类空间,每一个Web应用都有自己的类空间,Web应用之间通过各自的类加载器互相隔离。
如何做到Jar包共享防止JVM的内存膨胀?
通过ShareClassLoader,在双亲委托机制里面,各个加载器都可以通过父加载器去加载类,那么把需要共享的类放到父类加载器的路径即可。故Tomcat设置了ShareClassLoader,在WebAppClassLoader之上,解决了共享问题。如果Web自己加载不到,就委托Share来加载。
如何做到隔离Tomcat本身的类?
从上面的理解我们也能很清楚知道一共思想,要共享只能通过父子,要隔离只能通过兄弟。所以Tomcat又设置了一个类加载器CatalinaClassLoader,专门加载Tomcat自身的类。
那Tomcat和Web应用要共享呢?
再设置一个CommonClassLoader,作为CatalinaClassLoader和ShareClassLoader的父加载器。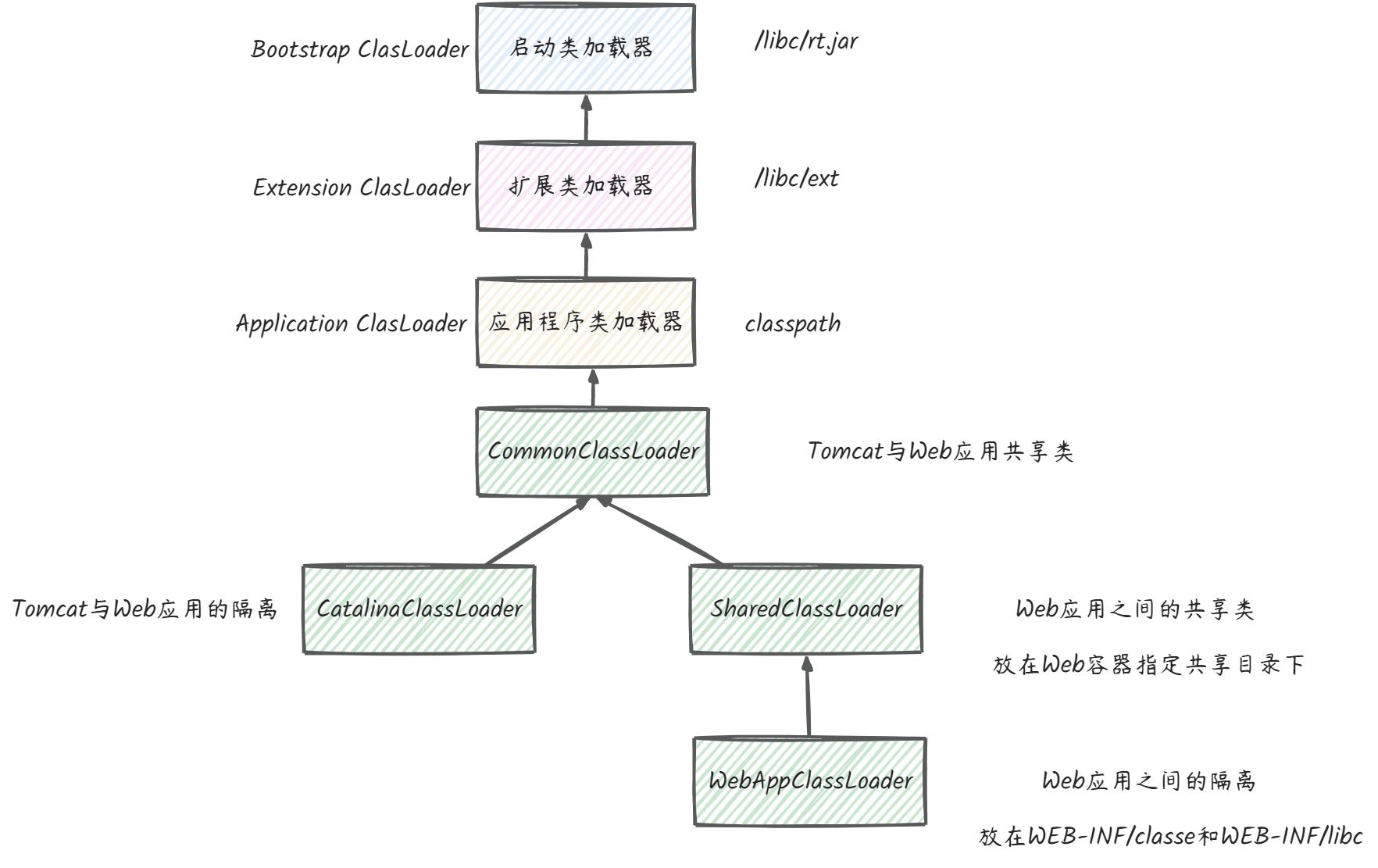
4.3 Spring加载问题
在JVM有一条隐含规则,默认情况,一个类由类加载器A加载,那么他的依赖类也是由相同的类加载器加载。Spring作为一个Bean工厂,它需要创建业务类实例,并在业务类实例之间加载这些类。Spring通过调用Class.forName来加载业务类:
public static Class<?> forName(String className) {
Class<?> caller = Reflection.getCallerClass();
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}会有调用者的Sprig的加载器去加载业务类。那么Web应用之间共享的Jar包可以交给ShareClassLoader来加载,从而避免重复。那么Spring本身也是由ShareClassLoader来加载,Spring本身又要去加载业务类。那么,问题来了,业务类Spring拿不到,因为ShareClassLoader没有,如何解决这个问题?
很简单,线程上下文加载器来了,和之前打破SPI机制一样,通过线程上下文来加载业务代码。这个类加载器保存在线程的私有数据,只要同一个线程设置了线程上下文加载器,在线程后续执行过程中,就能把这个类加载器取出来用。
Tomcat为每个Web应用创建WebAppClassLoader类加载器,并在启动Web应用里面设置上下文加载器。Spring启动时,就将线程上下文加载器取出来,用于加载器Bean。
cl = Thread.currentThread().getContextClassLoader();4.4 Dubbo自定义SPI
Dubbo在设计上,解决了原先SPI的资源浪费问题,且对SPI配置文件扩展和修改。
如下,将配置文件分成了三类目录:
- META-INF/service/目录:兼容JDK的SPI
- META-INF/dubbo/目录:存放用户自定义SPI配置文件
- META-INF/dubbo/internal/目录:用于存放Dubbo内部使用的SPI配置文件
并且将配置文件改为了KV的方式:
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol其中key被成为扩展名,当我们为一个接口查找具体实现类时,可以指定扩展名来选择相应的扩展实现。
其外,这种kv的设计,有利于我们去做问题的定位。假设我们使用的一个扩展实现类,jar包没有引入项目,那么抛出异常的时候,会携带扩展信息,而不是简单显示无法加载。
Dubbo在代码层面如何设计?
对于SPI来说,核心就是两个概念: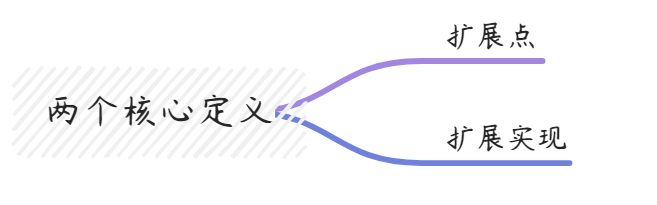
对于扩展点,使用了@SPI 注解:
@SPI("dubbo")
public interface Protocol {
}注解的vaule指定了默认的扩展名称,例如通过Dubbo SPI加载Protocol实现时,如果没有扩展名,会将注解vaule的值作为扩展名,即:
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol对于扩展加载器,使用方式如下,内部封装了所有的SPI逻辑:
Protocol protocol = ExtensionLoader
.getExtensionLoader(Protocol.class).getExtension("dubbo");接着看一下加载的过程,包括里面的一些核心自动:
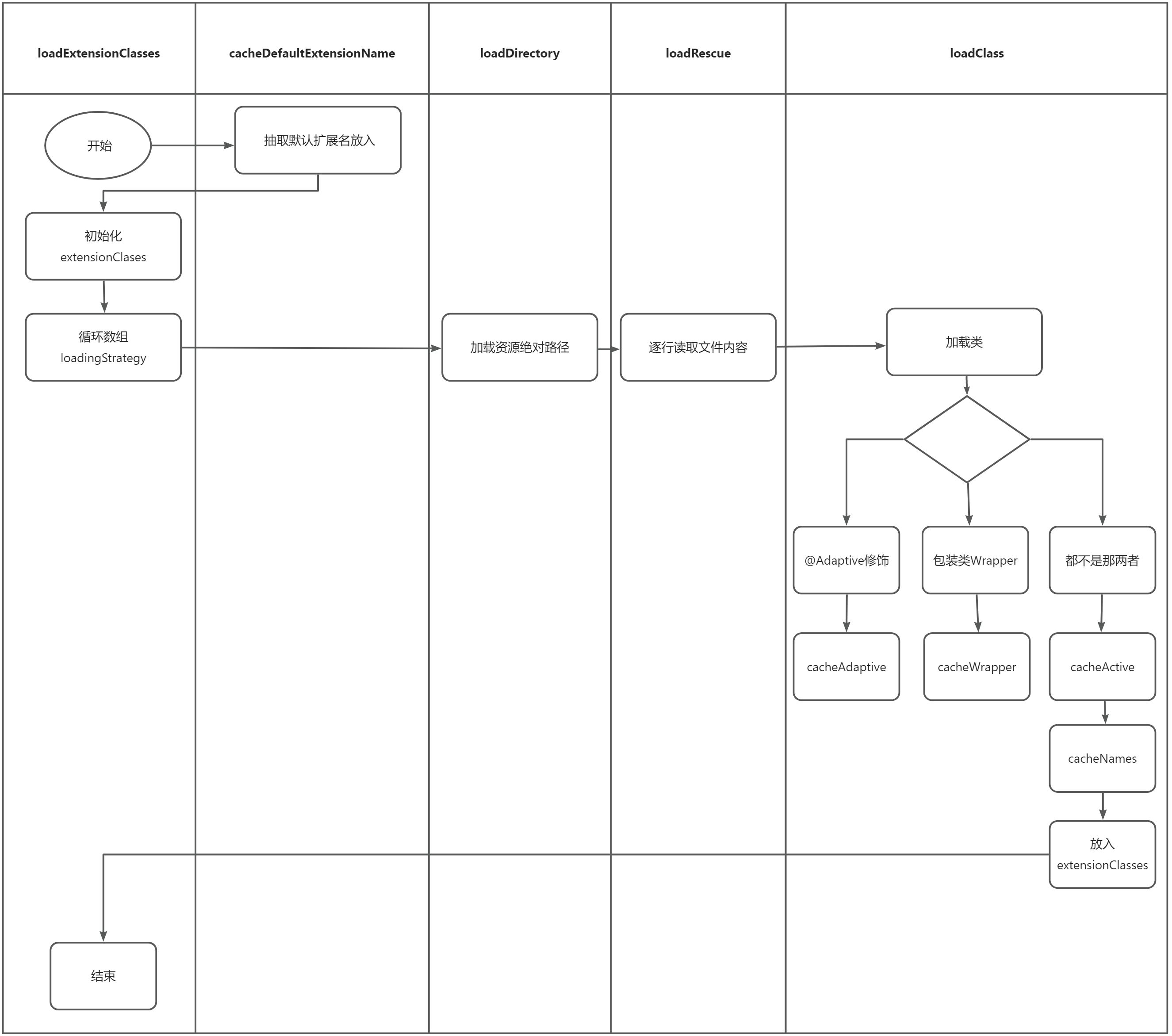
- 首先是这里的策略,有三个接口实现,优先级关系如下:
DubboInternalLoadingStrategy > DubboLoadingStrategy > ServicesLoadingStrategprivate static volatile LoadingStrategy[] strategies = loadLoadingStrategies();4.4.1 @SPI查找实例过程
内部做了一些类型的缓存等,这里不过多介绍,主要看查找过程:
- 这里extensionLoadersMap(ConcurrentMap类型),key为扩展接口,vaule为加载其扩展实现的ExtensionLoader 实例
private final ConcurrentMap<Class<?>, ExtensionLoader<?>> extensionLoadersMap = new ConcurrentHashMap<>(64);- 这里extensionInstances (ConcurrentMap类型),该集合缓存了扩展实现类与实例对象的映射关系。
private final ConcurrentMap<Class<?>, Object> extensionInstances
= new ConcurrentHashMap<>(64);获得对应的扩展类加载器:
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
ExtensionLoader<T> loader =
(ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type,
new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}拿到扩展加载实现类,就会调用实例逻辑:
- 这里的cachedInstances(ConcurrentMap类型)缓存了该ExtensionLoader 加载的扩展名与扩展实现对象之间的映射关系
private final ConcurrentMap<String, Holder<Object>> cachedInstances
= new ConcurrentHashMap<>();public T getExtension(String name) {
// getOrCreateHolder()方法中封装了查找cachedInstances缓存的逻辑
Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
if (instance == null) { // double-check防止并发问题
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// 根据扩展名从SPI配置文件中查找对应的扩展实现类
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}如果缓存不命中,则会创建实例,基于反射的方式进行:
- 该方法完成SPI配置文件的查找,以及相应扩展类的实例化,同时还实现了自动装配以及自动Wrapper包装等功能。
- 这里cachedNames缓存了改扩展实现类与扩展名之间的关系
- 这里cachedClasses缓存了改扩展名与扩展实现类之间的关系
private final ConcurrentMap<Class<?>, String> cachedNames = new ConcurrentHashMap<>();
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();他们两者之间互为映射关系,这让我想起zookeeper的设计
private T createExtension(String name) {
// 获取 cachedClasses 缓存,根据扩展名从 cachedClasses 缓存中获取扩展实现类。
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
// 根据扩展实现类从 EXTENSION_INSTANCES 缓存中查找相应的实例。
// 如果查找失败,会通过反射创建扩展实现对象。
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 自动装配扩展实现对象中的属性,即调用setter
injectExtension(instance);
// 自动包装扩展实现对象
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
//如果扩展实现类实现了Lifecycle接口,调用initialize() 方法进行初始化
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}4.4.2 IOC与信息加载
在前面,你应该可以看见在创建实例的过程中,提供了类的自动装配和自动包装,他是如何做到的?
// 自动装配扩展实现对象中的属性,即调用setter
injectExtension(instance);
// 自动包装扩展实现对象
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
} 这种自动装配和自动包装,毫无疑问,就是要获得全量信息,只有有信息者,才能有管理能力,所以从扩展类信息加载开始:
private void loadClass(){
... // 省略前面对@Adaptive注解的处理
} else if (isWrapperClass(clazz)) { // ---1
cacheWrapperClass(clazz); // ---2
} else ... // 省略其他分支
}可以看到它在这里,做了一些缓存的分类,那么自动包装就很简单:
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass
.getConstructor(type).newInstance(instance));
}
}同理,对于自动装配也是如此:
- 根据 setter 方法的名称以及参数的类型,加载相应的扩展实现,然后调用相应的 setter 方法填充属性,这就实现了 Dubbo SPI 的自动装配特性
private T injectExtension(T instance) {
if (objectFactory == null) { // 检测objectFactory字段
return instance;
}
for (Method method : instance.getClass().getMethods()) {
... // 如果不是setter方法,忽略该方法(略)
if (method.getAnnotation(DisableInject.class) != null) {
continue; // 如果方法上明确标注了@DisableInject注解,忽略该方法
}
// 根据setter方法的参数,确定扩展接口
Class<?> pt = method.getParameterTypes()[0];
... // 如果参数为简单类型,忽略该setter方法(略)
// 根据setter方法的名称确定属性名称
String property = getSetterProperty(method);
// 加载并实例化扩展实现类
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
method.invoke(instance, object); // 调用setter方法进行装配
}
}
return instance;
}这里发现,依赖于扩展Factory,即objectFactory,它有两个实现,分别如下:
- SpiExtensionFactory。,根据扩展接口获取相应的适配器,没有到属性名称
@Override
public <T> T getExtension(Class<T> type, String name) {
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
// 查找type对应的ExtensionLoader实例
ExtensionLoader<T> loader = ExtensionLoader
.getExtensionLoader(type);
if (!loader.getSupportedExtensions().isEmpty()) {
return loader.getAdaptiveExtension(); // 获取适配器实现
}
}
return null;
}- SpringExtensionFactory,将属性名称作为 Spring Bean 的名称,从 Spring 容器中获取 Bean
public <T> T getExtension(Class<T> type, String name) {
... // 检查:type必须为接口且必须包含@SPI注解(略)
for (ApplicationContext context : CONTEXTS) {
// 从Spring容器中查找Bean
T bean = BeanFactoryUtils.getOptionalBean(context,name,type);
if (bean != null) {
return bean;
}
}
return null;
}4.4.3 @Adaptive自适应扩展
在 Dubbo 中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。
这听起来有点矛盾,拓展方法未被调用,拓展就无法被加载。对于这个矛盾的问题,Dubbo 通过自适应拓展机制很好的解决了。自适应拓展机制的实现逻辑比较复杂,首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类。最后再通过反射创建代理类,整个过程比较复杂。
在上面的工厂中,其实除了那个两个,还有应该AdaptiveExtensionFactory,它就是一个适配器,根据运行时参数,选择对应的工厂。
对于标注了自适应相关的,在扩展信息加载的时候,会做一个缓存:
private void loadClass(){
if (clazz.isAnnotationPresent(Adaptive.class)) {
// 缓存到cachedAdaptiveClass字段
cacheAdaptiveClass(clazz, overridden);
} else ... // 省略其他分支
}它的类创建过于复杂,这里就不介绍了,总而言之,会做一个动态适配器类,总而言之,适配器的作用,就是按需选择。
4.4.4 @Active注解与自动激活特性
以 Dubbo 中的 Filter 为例说明自动激活特性的含义,org.apache.dubbo.rpc.Filter 接口有非常多的扩展实现类,在一个场景中可能需要某几个 Filter 扩展实现类协同工作,而另一个场景中可能需要另外几个实现类一起工作。这样,就需要一套配置来指定当前场景中哪些 Filter 实现是可用的,这就是 @Activate 注解要做的事情。
它提供了如下的字段选择:
- group 属性:修饰的实现类是在 Provider 端被激活还是在 Consumer 端被激活。
- value 属性:修饰的实现类只在 URL 参数中出现指定的 key 时才会被激活。
- order 属性:用来确定扩展实现类的排序。
一样是将这些信息做了缓存:
private void loadClass(){
if (clazz.isAnnotationPresent(Adaptive.class)) {
// 处理@Adaptive注解
cacheAdaptiveClass(clazz, overridden);
} else if (isWrapperClass(clazz)) { // 处理Wrapper类
cacheWrapperClass(clazz);
} else { // 处理真正的扩展实现类
clazz.getConstructor(); // 扩展实现类必须有无参构造函数
...// 兜底:SPI配置文件中未指定扩展名称,则用类的简单名称作为扩展名(略)
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
// 将包含@Activate注解的实现类缓存到cachedActivates集合中
cacheActivateClass(clazz, names[0]);
for (String n : names) {
// 在cachedNames集合中缓存实现类->扩展名的映射
cacheName(clazz, n);
// 在cachedClasses集合中缓存扩展名->实现类的映射
saveInExtensionClass(extensionClasses, clazz, n,
overridden);
}
}
}
}在获取对象的时候,传入URL,vaules,Group,最后返回扩展的实现类:
public List<T> getActivateExtension(URL url, String[] values,
String group) {
List<T> activateExtensions = new ArrayList<>();
// values配置就是扩展名
List<String> names = values == null ?
new ArrayList<>(0) : asList(values);
if (!names.contains(REMOVE_VALUE_PREFIX + DEFAULT_KEY)) {// ---1
getExtensionClasses(); // 触发cachedActivates等缓存字段的加载
for (Map.Entry<String, Object> entry :
cachedActivates.entrySet()) {
String name = entry.getKey(); // 扩展名
Object activate = entry.getValue(); // @Activate注解
String[] activateGroup, activateValue;
if (activate instanceof Activate) { // @Activate注解中的配置
activateGroup = ((Activate) activate).group();
activateValue = ((Activate) activate).value();
} else {
continue;
}
if (isMatchGroup(group, activateGroup) // 匹配group
// 没有出现在values配置中的,即为默认激活的扩展实现
&& !names.contains(name)
// 通过"-"明确指定不激活该扩展实现
&& !names.contains(REMOVE_VALUE_PREFIX + name)
// 检测URL中是否出现了指定的Key
&& isActive(activateValue, url)) {
// 加载扩展实现的实例对象,这些都是激活的
activateExtensions.add(getExtension(name));
}
}
// 排序 --- 2
activateExtensions.sort(ActivateComparator.COMPARATOR);
}
List<T> loadedExtensions = new ArrayList<>();
for (int i = 0; i < names.size(); i++) { // ---3
String name = names.get(i);
// 通过"-"开头的配置明确指定不激活的扩展实现,直接就忽略了
if (!name.startsWith(REMOVE_VALUE_PREFIX)
&& !names.contains(REMOVE_VALUE_PREFIX + name)) {
if (DEFAULT_KEY.equals(name)) {
if (!loadedExtensions.isEmpty()) {
// 按照顺序,将自定义的扩展添加到默认扩展集合前面
activateExtensions.addAll(0, loadedExtensions);
loadedExtensions.clear();
}
} else {
loadedExtensions.add(getExtension(name));
}
}
}
if (!loadedExtensions.isEmpty()) {
// 按照顺序,将自定义的扩展添加到默认扩展集合后面
activateExtensions.addAll(loadedExtensions);
}
return activateExtensions;
}4.4.5 dubbo的方案总结
从最上面微内核架构,我们其实也能很容易理解为什么dubbo要自己实现一套SPI方案,简单来说就是做到复用,共享资源,减少每次链路上重新创建的性能损耗,以及给dubbo的功能上,提供更多的功能特性,从而支持更多复杂的业务需求。
4.5 springboot的spi机制
最后再来分享点简单的,不知道大家是否有自己开发过springboot-starter,他是如何做到你引入就可以直接使用?是如何被你应用所感知的?是如何做到自动装配?
它底层是利用了springt的spi机制,Spring SPI对 Java SPI 进行了封装增强。我们只需要在 META-INF/spring.factories 中配置接口实现类名,即可通过服务发现机制,在运行时加载接口的实现类。
@Test
public void testSpringSpi() {
List<HelloSpi> helloSpiList = SpringFactoriesLoader.loadFactories(HelloSpi.class,this.getClass().getClassLoader());
Iterator<HelloSpi> iterator = helloSpiList.iterator();
while (iterator.hasNext()) {
HelloSpi next = iterator.next();
System.out.println(next.getName() + " 准备执行");
next.handle();
}
System.out.println("执行结束");
}用法几乎和java的spi机制一模一样。那么对于starter来说,也是用了Spring的SPI。如下我们简单的组件,我希望它做到自动装配:
- 这里实现了EnvironmentAware,使得它有感知配置的能力。
@Configuration
public class DataSourceAutoConfig implements EnvironmentAware {
/**
* 数据源配置组
*/
private Map<String, Map<String, Object>> dataSourceMap = new HashMap<>();
/**
* 默认数据源配置
*/
private Map<String,Object> defaultDataSourceConfig;
/**
* 分库数量
*/
private int dbCount;
/**
* 分表数量
*/
private int tbCount;
/**
* 路由字段
*/
private String routerKey;
/**
* 封装数据源
* @return 数据源配置封装
*/
@Bean
public DBRouterConfig dbRouterConfig() {
return new DBRouterConfig(dbCount, tbCount, routerKey);
}
/**
* 切点配置
*/
@Bean (name = "db-router-point")
@ConditionalOnMissingBean
public DBRouterJoinPoint point(DBRouterConfig dbRouterConfig,IDBRouterStrategy dbRouterStrategy) {
return new DBRouterJoinPoint(dbRouterConfig,dbRouterStrategy);
}
/**
* 返回拦截器
*/
@Bean
public Interceptor plugin() {return new DynamicMybatisPlugin();}
/**
* 封装策略接口,进行配置
* @param dbRouterConfig
* @return 返回策略信息
*/
@Bean
public IDBRouterStrategy dbRouterStrategy(DBRouterConfig dbRouterConfig) {
return new DBRouterStrategyHashCode(dbRouterConfig);
}
/**
* 数据源的创建
*/
@Bean
public DataSource dataSource(){
//创建数据源
Map<Object,Object> targetDataSources = new HashMap<>();
for(String dbInfo : dataSourceMap.keySet()) {
Map<String,Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo,new DriverManagerDataSource(objMap.get("url").toString(),
objMap.get("username").toString(),objMap.get("password").toString()));
}
//设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(new DriverManagerDataSource(defaultDataSourceConfig.get("url").toString(),
defaultDataSourceConfig.get("username").toString(),defaultDataSourceConfig.get("password").toString()));
return dynamicDataSource;
}
/**
* 事务管理
*/
@Bean
public TransactionTemplate transactionTemplate(DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dataSource);
TransactionTemplate transactionTemplate = new TransactionTemplate();
transactionTemplate.setTransactionManager(dataSourceTransactionManager);
transactionTemplate.setPropagationBehaviorName("PROPAGATION_REQUIRED"); //事务传播
return transactionTemplate;
}
/**
* 数据源配置与提取
* @param environment
*/
@Override
public void setEnvironment(Environment environment) {
String prefix = "mini-db-router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
routerKey = environment.getProperty(prefix + "routerKey");
// 分库分表数据源
String dataSources = environment.getProperty(prefix + "list");
assert dataSources != null;
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
// 默认数据源
String defaultData = environment.getProperty(prefix + "default");
defaultDataSourceConfig = PropertyUtil.handle(environment, prefix + defaultData, Map.class);
}
}在spring.factories中指定内容,然后引入maven仓库后,就可以直接使用:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=cn.HuanXin.middleware.db.router.config.DataSourceAutoConfig5、扩展实现自己的SPI方案
在前面,已经介绍并理解了每种SPI的实现目标,对于本次任务来说,我想实现的目标,与dubbo的spi机制更为相似。我需要设计以下几点:
- 扩展实现自己的SPI,避免频繁的reload带来的资源开销
- 对于端到端的流量,最好能够复用每次的资源
- 符合微内核设计,对后续的扩展足够友好
5.1 核心概念
对于本次开发,我们注意两个核心概念,扩展点,即描述接口;扩展实现,即扩展点的具体实现。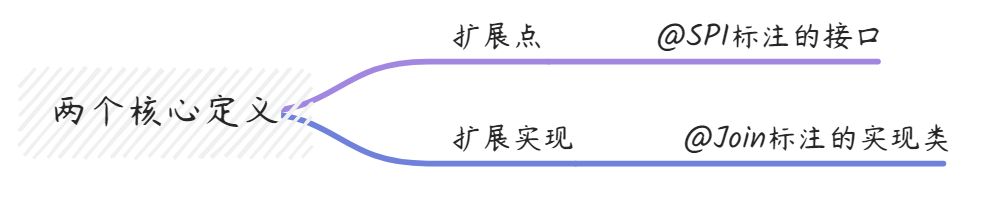
对于扩展点,对于没有指定的情况下,应该提供默认的实现:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface SPI {
String value() default ""; // 扩展点的默认实现
}
对于扩展实现,我们有很多,所以需要进行一个排序处理,对于一些插件,为了更多场景适配,可以提供单例模式:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Join {
int order() default 0; // 多个扩展实现排序
boolean isSingleton() default true; // 是否单例,对于某些情况做性能优化
}5.2 实现方案概述
整个的流程如下,核心分为三部分(信息封装+缓存设计+类加载)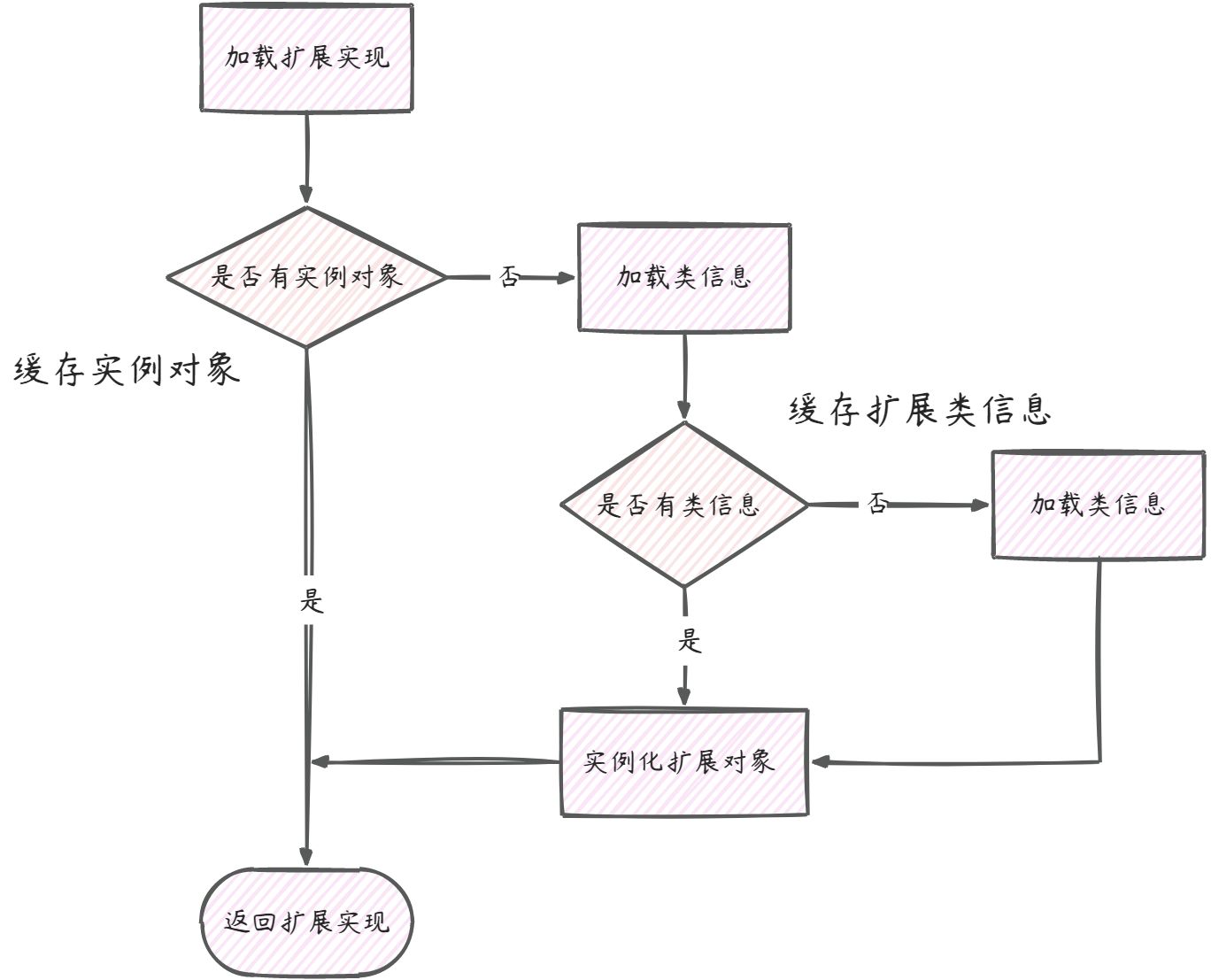
5.3 类信息定义
因为我们这里定义了顺序、单例判断、以及别名等,因为在配置信息中,我们的格式是以KV的方式存储,所以我们需要对类的信息做一个额外的封装,以及对实例对象也做一个封装:
// 扩展实现包装类,持有实现对象
private static final class Holder<T> {
private volatile T value; // 内存可见性
private Integer order;
private boolean isSingleton;
public T getValue() {
return value;
}
public void setValue(final T value) {
this.value = value;
}
public void setOrder(final Integer order) {
this.order = order;
}
public Integer getOrder() {
return order;
}
public boolean isSingleton() {
return isSingleton;
}
public void setSingleton(final boolean singleton) {
isSingleton = singleton;
}
}
// 对扩展实现的信息进行封装
private static final class ClassEntity {
private String name;
private Integer order;
private Boolean isSingleton;
private Class<?> clazz;
private ClassEntity(final String name,final Integer order,final Class<?> clazz,final boolean isSingleton) {
this.name = name;
this.order = order;
this.clazz = clazz;
this.isSingleton = isSingleton;
}
private String getName() {
return name;
}
private Integer getOrder() {
return order;
}
private Class<?> getClazz() {
return clazz;
}
private void setClazz(final Class<?> clazz) {
this.clazz = clazz;
}
public Boolean isSingleton() {
return isSingleton;
}
}5.4 缓存设计
在上面,我们也可以知道,我们区别于传统SPI的特点,一个就是缓存的设计,一个就是加载的粒度:
private static final Map<Class<?>, ExtensionLoader<?>> LOADERS = new ConcurrentHashMap<>();
// 加载器本身信息,包括实现类的缓存
private final Class<T> clazz;
private final ClassLoader classLoader; // 类加载
private Holder<Map<String,ClassEntity>> cachedClasses = new Holder<>(); // 缓存的已加载的实现类信息,实现类别名 -> 实现类信息
private final Map<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>(); // 缓存的已加载的实现类实例的值包装器, 实现类别名 -> 实现类实例包装
private final Map<Class<?>,Object> joinInstances = new ConcurrentHashMap<>(); //缓存的已加载的实现类实例,实现类类型 -> 实现类实体
private String cachedDefaultName; // 缓存默认名称,来源于@SPI注解的value()方法非空白返回值
private final Comparator<Holder<Object>> holderComparator = Comparator.comparing(Holder::getOrder); // 比较器,降序
private final Comparator<ClassEntity> classEntityComparator = Comparator.comparing(ClassEntity::getOrder); // 比较器5.5 加载实现
加载实现的逻辑比较简单,现成的SPI实现有很多参考,这里贴一下逻辑即可,注意在设计的过程中,处理好并发的问题:
// 需要传入SPI,以及类加载器,获得工厂
public static <T> ExtensionLoader<T> getExtensionLoader(final Class<T> clazz,final ClassLoader cl) {
Objects.requireNonNull(clazz, "extension clazz is null");
if (!clazz.isInterface()) {
throw new IllegalArgumentException("Extension clazz is not interface");
}
if(!clazz.isAnnotationPresent(SPI.class)) {
throw new IllegalArgumentException("Extension clazz is not spi");
}
ExtensionLoader<T> extensionLoader = (ExtensionLoader<T>) LOADERS.get(clazz);
if(Objects.nonNull(extensionLoader)) {
return extensionLoader;
}
LOADERS.putIfAbsent(clazz, new ExtensionLoader<>(clazz,cl));
return (ExtensionLoader<T>) LOADERS.get(clazz);
}
// 加载具体的类实现,并返回扩展实现类
public T getJoin(final String name) {
if(StringUtils.isBlank(name)) {
throw new NullPointerException("get join name is null");
}
Holder<Object> objectHolder = cachedInstances.get(name);
// 这里也使用DCL去cachedInstances缓存中取别名对应的值持有器,值持有器为空则创建
if (Objects.isNull(objectHolder)) {
cachedInstances.putIfAbsent(name, new Holder<>());
objectHolder = cachedInstances.get(name);
}
Object value = objectHolder.getValue();
if(Objects.isNull(value)) {
synchronized (cachedInstances) {
if(Objects.isNull(value)) {
createExtension(name,objectHolder);
value = objectHolder.getValue();
if (!objectHolder.isSingleton()) {
Holder<Object> removeObj = cachedInstances.remove(name); // 返回杯移除的对象
removeObj = null; // 避免内存泄露
}
}
}
}
return (T)value;
}5.6 演示与结果
最后,基于我们设计的SPI,做了如下的测试:
@Test
public void testLoader() {
System.out.println(ExtensionLoader.getExtensionLoader(JdbcSPI.class).getDefaultJoin().getClassName());
System.out.println(ExtensionLoader.getExtensionLoader(JdbcSPI.class).getJoin("mysql").getClassName());
System.out.println(ExtensionLoader.getExtensionLoader(JdbcSPI.class).getJoin("oracle").getClassName());
}
@Test
public void testFactory() {
ExtensionFactory extensionFactory = ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getDefaultJoin();
System.out.println(extensionFactory.getExtension("mysql", JdbcSPI.class).getClassName());
}堆栈的布局如下:
6、总结
从上面的分析,基于Java原生SPI设计思路上设计出来的SPI框架具备了松耦合、高易用性和高扩展性的特点,并且添加了加载实例缓存、并发安全等特性,填补了原生JDK中SPI的一些缺陷。在很多中间件的设计,正是由于此强大的SPI模块的存在,才能让其他模块,快速实现功能扩展,提供丰富的动态性能。


